Анекдот про фермера
Налоговый инспектор фермеру:
— А вы не утаивайте, не утаивайте! В конце концов ваши деньги к вам же и возвращаются: ну, знаете, субсидии, дотации…
— Понятно. Вот сейчас отрежу хвост у собаки, чтобы и ей было что на обед.
Налоговый инспектор фермеру:
— А вы не утаивайте, не утаивайте! В конце концов ваши деньги к вам же и возвращаются: ну, знаете, субсидии, дотации…
— Понятно. Вот сейчас отрежу хвост у собаки, чтобы и ей было что на обед.
Добавлены комментарии в блоге.
В качестве движка используется gitalk.
Как его добавить в light-тему Hexo:
Создайте репозиторий для хранения Issues. Я создал с названием gitalk.
Создайте приложение в github: тынц.
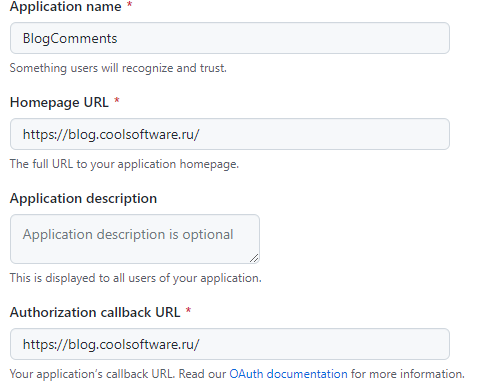
Это приложение потом можно будет увидеть в списке Settings / Developer settings.
Сгенерируйте “секрет” (Generate a new client secret); запомните (запишите) его.
В light-теме Hexo в layout\_partial создайте файл gitalk_comment.ejs со следующим содержанием:
<div id="gitalk-container" style="margin: 30px;"></div> |
В layout\_partial\comment.ejs подключите gitalk_comment.ejs:
<% if (theme.comment_provider == "gitalk") { |
В _config.yml light-темы включите использование gitalk-комментариев:
comment_provider: gitalk |
В корневом _config.yml вашего блога выполните настройку gitalk:
# gitalk comment |
clientID - значение Client ID из настроек приложения, созданного на шаге 2.clientSecret - “секрет” (Client secret), созданный на шаге 3.repo - название репозитория (шаг 1).owner и admin - имя Вашего пользователя в Github.Если при установке соединения вылазит ошибка:
10:57 AM OpenSSL: error:0A00018E:SSL routines::ca md too weak |
, то нужно отредактировать настройки на вкладке ADVANCED: промотать до пункта Enable Custom Options, включить его и ввести в Custom Options:
tls-cipher "DEFAULT:@SECLEVEL=0" |
Я считаю, что поиск по блогу - “must-have feature”. К сожалению, в выбранной мною простенькой теме hexo-light поиска не предусмотрено. Поэтому, нужно либо использовать сервисы типа Гугл или Яндекс, либо автоматически создавать индексный файл (xml или json) каждый раз при перегенерации блога и реализовать поиск на клиенте с помощью javascript. Я решил идти по второму пути.
Для генерации индекса выбран плагин для hexo: hexo-generator-searchdb. Устанавливается он с помощью:
npm install hexo-generator-searchdb |
Конфигурирование делается в _config.yml блога:
search: |
Следующим шагом нужно создать страницу для поиска. Делается это так:
hexo new page "search" |
В source каталоге создастся подкаталог search и в нем index.md. Содержание надо сделать наподобие такого:
--- |
Я добавил layout search в тему hexo-theme-light-plus. title лучше оставить пустым, тогда в качестве заголовка страницы поиска будет использоваться локализованная строка “search”.
Скрипт для поиска лежит в js/local-search.js. Я его сделал на основе вот этого. Убрал “popup”. Сделал постраничный показ результатов поиска (по 10 на страницу). Настройки в самом local-search.js:
const CONFIG = { |
В общем, получилось так: поиск.
При обновлении MySQL Server на CentOS вылезла ошибка:
The GPG keys listed for the "MySQL 8.0 Community Server" repository are already installed but they are not correct for this package. |
Победить можно выполнив команду:
rpm --import https://repo.mysql.com/RPM-GPG-KEY-mysql-2022 |
Гугл прислал письмо о том, что бесплатная версия G Suite прекратит работать с 1 июля 2022 года. И это послужило толчком для переезда блога с blogspot на другую платформу. После недолгих поисков подходящего движка для блога, я остановил свой выбор на Hexo (https://hexo.io).
Тему для блога я выбрал простенькую “light”, которую пришлось немного “допилить”. “Допиленная” тема получила название “light plus” и лежит тут: https://github.com/coolsoftware/hexo-theme-light-plus
В теме было сделано следующее:
Кроме работы над темой, пришлось разбираться с импортом записей из старого блога. Для миграции из blogger в hexo нашелся “hexo-migrator-blogger”. Однако, он сильно устарел, некоторые зависимости уже не устанавливаются. А кроме того, мне хотелось, чтобы сохранились все внешние ссылки на записи. Поэтому пришлось писать свой “мигратор”: https://github.com/coolsoftware/hexo-migrator-blogspot.
Чтобы сохранить ссылки на существующие посты нужно:
В новом блоге сделать такую же структуру записей, что была в старом, т.е. /<год>/<месяц>/<заголовок>. _config.yml:
permalink: :year/:month/:name/ |
Прописать mod_rewrite-правила (для Апача):
RewriteEngine on |