Мой компьютер (контекстное меню) –> Управление -> Службы (Рис. 1): Вспомогательная служба IP –> Тип запуска –> Выбираем из списка: Автоматически
Пуск –> Выполнить –> regedit
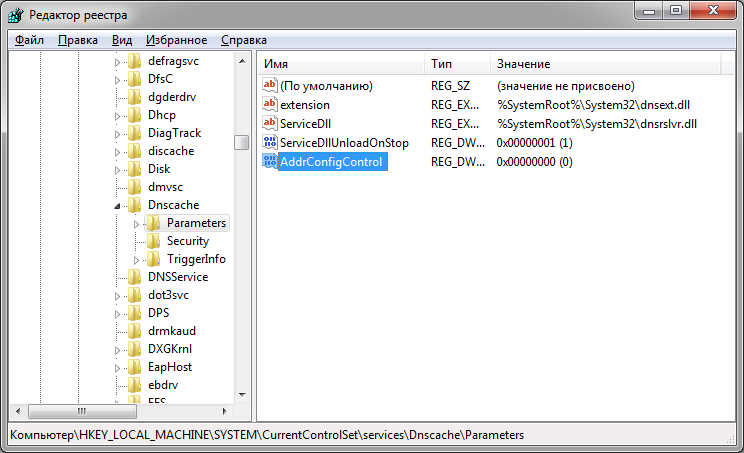
В реестре по адресу HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\services\Dnscache\Parameters создать ключ AddrConfigControl типа DWORD со значением 0 (Рис. 2).
Пуск –> Панель управления –> Сеть и Интернет –> Сетевые подключения –> Подключение по локальной сети –> Свойства (Рис. 3): Протокол Интернета версии 6 (TCP/IPv6) –> включить и в Свойствах указать: Использовать следующие адреса DNS-серверов: Предпочитаемый DNS-сервер: 2001:4860:4860::8888 Альтернативный DNS-сервер: 2001:4860:4860::8844
Пуск –> Выполнить –> gpedit.msc
Конфигурация компьютера –> Административные шаблоны –> Сеть –> Параметры TCP/IP –> Технологии Туннелирования IPv6 (Рис. 4): Классификация Teredo по умолчанию –> Включить –> Включенное состояние Частота обновления Teredo –> Включить –> 10 Состояние Teredo –> Включить –> Корпоративный клиент Порт клиента Teredo -> Не задано Имя сервера Teredo –> Включить –> Выбираем из списка: teredo.remlab.net
Пуск – Выполнить – cmd: netsh int ipv6 delete route ::/0 Teredo netsh int ipv6 add route ::/0 Teredo
Полезные ссылки, касающиеся разработки под Raspberry Pi. Пишу главным образом для себя, чтобы не забыть :) Пост будет время от времени дополнятся (я надеюсь :)
б) сперва лучше (imho) залить образ на флешку ( sudo dd bs=1M if=2015-02-16-raspbian-wheezy.img of=/dev/sdb ), вставить флешку в Raspberry Pi, установить апдейты и библиотеки (например, для разработки под X11: http://doc.qt.io/qt-5/linux-requirements.html), потом сделать образ этой флешки ( sudo dd bs=1M if=/dev/sdb of=rasp-pi.img ) и уже с ним работать дальше.
в) “Магическое” число 62914560 ( sudo mount -o loop,offset=62914560 rasp-pi.img/mnt/rasp-pi-rootfs ) можно вычислить следующим образом:
[vitaly@localhost opt]$ sudo fdisk -l rasp-pi.img
Disk rasp-pi.img: 7892 MB, 7892631552 bytes, 15415296 sectors Units = sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disk label type: dos Disk identifier: 0x0009bf4f
Устр-во Загр Начало Конец Блоки Id Система rasp-pi.img1 8192 122879 57344 c W95 FAT32 (LBA) rasp-pi.img2 122880 6399999 3138560 83 Linux
122880 - это начало раздела (номер первого сектора раздела), который нужно подмонтировать. 122880 * 512 = 62914560.
Троттлинг (throttling) - это регулирование (ограничение) скорости какого-нибудь процесса. Например, bandwidth throttling - регулирование пропускной способности канала (обычно измеряется в килобайтах в секунду, kB/s).
В листинге ниже показано, как можно реализовать троттлинг.
for (int i = 0; i < 1000; i++) { while (!throttle_acquire()); //цикл ожидания doWork(); //выпоняем работу }
В этом примере процесс состоит из 1000 итераций. Каждая итерация заключается в вызове функции doWork(), которая, например, отправляет очередную порцию данных. Ограничение скорости заключается в введении лимита на количество этих вызовов N за период времени dT. Перед вызовом doWork() осуществляется проверка превышения лимита: функция throttle_acquire() возвращает false, если лимит превышен, и true, в противном случае.
Троттлинг можно реализовать с использованием кольцевого буфера. Этот кольцевой буфер заполняется моментами времени последних вызовов функции doWork() (см пример выше). Размер буфера равен максимально разрешенному количеству этих вызовов N за период времени dT. Если буфер полностью заполнен, то функция acquire() возвращает false. Это означает, что необходимо подождать, пока из буфера не будет удален хотя бы один момент времени, который располагается от текущего момента (“сейчас”) дальше, чем dT.
1. Скачиваем zlib 1.2.8 с http://www.zlib.net/ 2. Распаковываем архив в c:\zlib-1.2.8 3. Открываем в Visual Studio 2010 проект C:\zlib-1.2.8\contrib\vstudio\vc10\zlibvc.sln 4. Меняем следующие настройки проекта zlibstat:
6. Открываем в Visual Studio 2010 любой проект C++ и открываем Property Manager->(Project Name)->Debug | Win32->Microsoft.Cpp.Win32.user->Common Properties->VC++ Directories. Добавляем c:\zlib-1.2.8 в Include Directories, Library Direcories и Source Directories.
=== Перепечатка материалов блога разрешается с обязательной ссылкой на blog.coolsoftware.ru
Понадобилось мне создать пару открытый/закрытый ключ на C#. Я поискал немного и нашел замечательную криптографическую библиотеку под названием Bouncy Castle: https://www.bouncycastle.org/. Для C# исходники можно скачать здесь: http://www.bouncycastle.org/csharp/. Ниже описан порядок установки и использования.
Качаем bccrypto-net-1.7-src.zip, распаковываем в какой-нибудь каталог на диске.
Открываем проект csharp.sln в Visual Studio 2010.
В свойствах проекта crypto в Build->General->Conditional compilation symbols комментируем INCLUDE_IDEA.
Пробуем выполнить Build и видим ошибки: error CS1504: Source file ‘C:\temp\csharp\crypto\src\crypto\engines\IDEAEngine.cs’ could not be opened (‘Неопознанная ошибка ‘) error CS1504: Source file ‘C:\temp\csharp\crypto\test\src\crypto\test\IDEATest.cs’ could not be opened (‘Неопознанная ошибка ‘) error CS1504: Source file ‘C:\temp\csharp\crypto\src\asn1\misc\IDEACBCPar.cs’ could not be opened (‘Неопознанная ошибка ‘)
Удаляем из проекта crypto отсутствующие файлы: src\crypto\engines\IDEAEngine.cs src\asn1\misc\IDEACBCPar.cs test\src\crypto\test\IDEATest.cs
Пробуем еще раз выполнить Build - на этот раз все должно получиться и будет создана библиотека crypto.dll.
Прописываем созданную библиотеку в References проекта.
Код для генерации пары открытый/закрытый ключ приведен ниже. Открытый ключ - в формате PKCS#8. Закрытый ключ - в формате PKCS#1.
using Org.BouncyCastle.Asn1.Pkcs; using Org.BouncyCastle.Asn1.X509; using Org.BouncyCastle.Crypto; using Org.BouncyCastle.Crypto.Parameters; using Org.BouncyCastle.Pkcs; using Org.BouncyCastle.Security; using Org.BouncyCastle.X509; using Org.BouncyCastle.Crypto.Generators; RsaKeyPairGenerator rsa = new RsaKeyPairGenerator(); rsa.Init(new KeyGenerationParameters(new Org.BouncyCastle.Security.SecureRandom(), 1024)); AsymmetricCipherKeyPair pair = rsa.GenerateKeyPair(); PrivateKeyInfo privateKeyInfo = PrivateKeyInfoFactory.CreatePrivateKeyInfo(pair.Private); byte[] serializedPrivateBytes = privateKeyInfo.PrivateKey.ToAsn1Object().GetDerEncoded(); string privateKey = Convert.ToBase64String(serializedPrivateBytes); SubjectPublicKeyInfo publicKeyInfo = SubjectPublicKeyInfoFactory.CreateSubjectPublicKeyInfo(pair.Public); byte[] serializedPublicBytes = publicKeyInfo.ToAsn1Object().GetDerEncoded(); string publicKey = Convert.ToBase64String(serializedPublicBytes);
=== Перепечатка материалов блога разрешается с обязательной ссылкой на blog.coolsoftware.ru
Оказалось, что организовать вызов Perl-скриптов из C/C++ (MS Visual C++ 2010) достаточно просто:
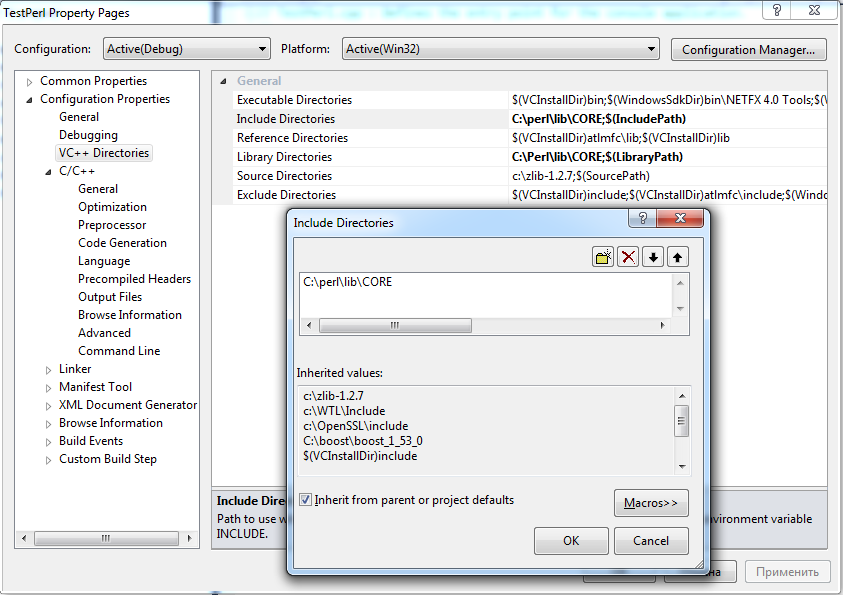
Прописываем в Include Directories и Library Directories проекта путь к Perl\CORE:
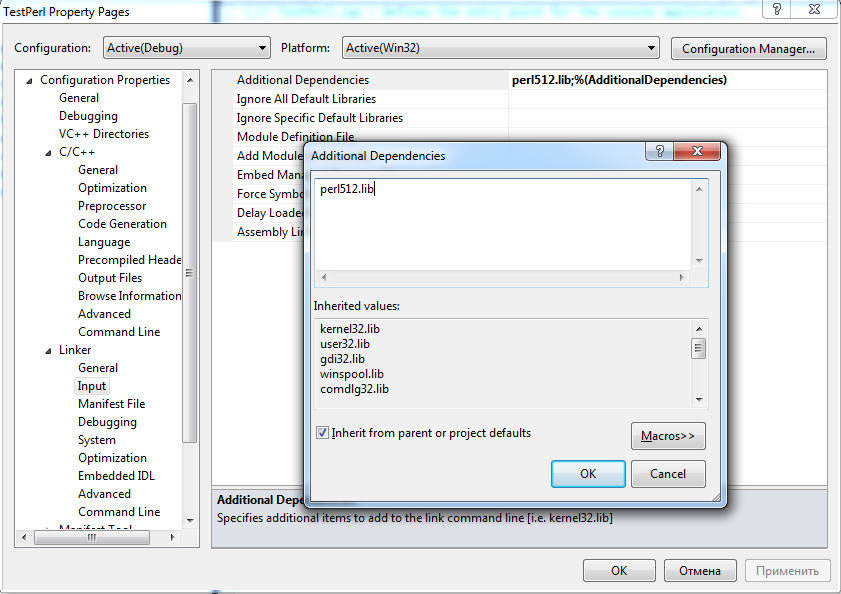
Добавляем perl512.lib в Linker->Input->Additional Dependencies.
Ниже приведен пример кода, вызывающего perl из консольного приложения C++. Обращу внимание на два момента: a) #pragma warning (disable:4005) для подавления сообщения компилятора “‘ENOTSOCK’ : macro redefinition“; b) если опустить вызов PERL_SYS_INIT(0, NULL), то на шаге perl_parse получим Access Violation.
Я уже несколько раз сталкивался с необходимостью решать следующую задачу: есть список интервалов и нужно найти один или все интервалы, в которые входит заданное значение. Пример: есть список диапазонов IP-адресов, каждому диапазону присвоен двух-буквенный код страны. Требуется для заданного IP-адреса определить страну.
Когда интервалов не много, то можно обойтись полным перебором (brute-force). Но когда их несколько десятков тысяч, а искать приходится часто, то нужна оптимизация.
Подходящая структура для быстрого поиска в списке интервалов называется “Дерево Интервалов” (Interval Tree) или “Дерево Отрезков”. Хорошее описание (англ.), а также пример реализации я нашел тут: http://www.drdobbs.com/cpp/interval-trees/184401179.
Теория
Коротко описание структуры дерева отрезков и алгоритма поиска приведу на примере: пусть есть список именованных отрезков:
Массив X содержит 10 элементов: X[0], X[1], …, X[9]. Возьмем среднее значение (медиану): 83 = X[m], m = (9-0) div 2.
Возможны три варианта расположения отрезков относительно медианы: 1. отрезки, которые содержат медиану. 2. отрезки, которые лежат слева от медианы. 3. отрезки, которые лежат справа от медианы.
Создадим узел дерева, который будет включать в себя значение медианы (дискриминант = 83) и список всех отрезков, которые содержат медиану:
R = {83, [c, f, g, h, i, j]}
Оставшиеся отрезки слева от R: {a, b, d, e} и справа от R: {k, l, m}.
Построим левый узел дерева для отрезков {a, b, d, e}, находящихся левее медианы, рассматривая вершины слева от медианы: {75, 76, 79, 80}. Получим: O = {76, [a, b, d]}. Аналогично правый узел для отрезков {k, l, m} и вершин {84, 85, 90, 91, 92}: U = {90, []}. Обратите внимание на возможность существования узлов, не содержащих отрезков. Продолжая процесс рекурсивно, получим следующие узлы: N = {75, []}, P = {79, [e]}, S = {84, [k]}, V = {91, [l, m]}, Q = {80, []}, T = {85, []}, W = {92, []}.
R / \ O U / \ / \ N P S V \ \ \ Q T W
Висячие вершины N, Q, T и W можно убрать. Окончательно получим дерево:
R / \ O U \ / \ P S V
Алгоритм поиска выглядит следующим образом. Начинаем с вершины дерева. Сравниваем дискриминант текущего узла с искомым значением q. Если они равны (случай 1), то выводим все отрезки, на которые указывает текущий узел, и завершаем процесс. Если дискриминант текущего узла больше, чем q (случай 2), то перебираем все отрезки, на которые указывает текущий узел, и выводим такие, которые содержат q. Затем переходим к левому узлу. Если дискриминант текущего узла меньше, чем q (случай 3), то аналогично перебираем все отрезки текущего узла и выводим те, которые содержат q, а затем переходим к правому узлу.
В двух последних случаях (когда дискриминант узла не равен q) нужен перебор отрезков, на которые указывает узел. Этот перебор можно оптимизировать, если иметь два отсортированных массива отрезков: первый массив AL должен быть отсортирован по возрастанию левой (меньшей) координаты отрезка, а второй массив DH должен быть отсортирован по убыванию правой (большей) координаты отрезка. Для узла R из нашего примера:
AL = {c, f, g, h, i, j} DH = {g, i, j, h, c, f}
Тогда, если дискриминант узла больше q (случай 2), то перебираем отрезки из массива AL до тех пор, пока левая координата отрезка не будет больше q. Если дискриминант узла меньше q (случай 2), то перебираем отрезки из массива DH до тех пор, пока правая координата отрезка не будет меньше q.
За основу я взял реализацию Yogi Dandass, в которую добавил некоторые недостающие (ommited) определения, исправил пару багов и существенно оптимизировал построение дерева (метод construct_tree).
Баг 1 в методе itree::construct_tree. Код ниже вызывал выход за границы массива.
Баг 2 в методе query_iterator::init_node. Если value == cur_node->discrim, то требуется проверка, что cur_node->size != 0, а иначе возможен выход за границы массива.
1. Классы VLock, VRWLock, VLockPtr, VReadLockPtr, VWriteLockPtr теперь “uncopyable”, то есть их нельзя скопировать (см. Листинг 1: Ошибка 1 и Ошибка 2). Запрет на копирование осуществляется путем наследования этих классов от VUncopyable. При компиляции кода, содержащего запрещенное копирование, будет выдано сообщение ошибке:
VLock.h(62): error C2248: ‘VUncopyable::VUncopyable’ : cannot access private member declared in class ‘VUncopyable’
2. Конструктор класса VRWLock объявлен с ключевым словом explicit для того, чтобы исключить неявное создание экземпляра этого класса при вызове функции (см. Листинг 1: Ошибка 3). При компиляции кода, содержащего такое неявное создание VRWLock, будет выдано сообщение об ошибке:
TestLock.cpp(184): error C2664: ‘RWFunc’ : cannot convert parameter 1 from ‘int’ to ‘const VRWLock &’ Reason: cannot convert from ‘int’ to ‘const VRWLock’ Constructor for class ‘VRWLock’ is declared ‘explicit’
LockLib это набор классов для организации доступа к разделяемым ресурсам в программе на C++ под Windows. Исходники доступны на GitHub: https://github.com/coolsoftware/LockLib.
class VLock
Класс VLock используется как альтернатива CRITICAL_SECTION (на самом деле это “обертка” над CRITICAL_SECTION).
void Lock(int lPosition, volatile LONG * lpThreadLock = NULL)
Блокировка ресурса для монопольного использования. Если ресурс уже кем-то заблокирован, то происходит ожидание когда ресурс снова станет свободен и его удастся заблокировать.
Параметр lPosition служит для идентификации места вызова метода Lock и может использоваться при отладке.
Необязательный параметр lpThreadLock служит для подсчета вызовов метода Lock в текущем потоке. Подробности смотрите ниже в разделе посвященном lpThreadLock.
void Unlock(volatile LONG * lpThreadLock = NULL)
Снятие блокировки.
static void OutputDebugLocks()
При отладке и оптимизации приложений иногда нужно видеть список всех существующих блокировок и статистику по ним: сколько в данный момент активных блокировок, в каком месте они заблокированы. Посмотреть такую статистику можно вызвав OutputDebugLocks. Эта статистика доступна в Debug-версии приложении, когда объявлен _DEBUG, или когда объявлен макрос DEBUG_LOCK.
volatile LONG * lpThreadLock
Проблема с блокировками в много-поточном приложении связана с тем, что поток, который установил блокировку, может быть остановлен с помощью TerminateThread. В этом случае Unlock не будет вызван никогда и блокировка ресурса “повиснет”, а другие потоки, которые попытаются заблокировать этот ресурс, также “повиснут”. Чтобы разрулить эту ситуацию, необходимо вести подсчет блокировок для каждого потока и вызывать Unlock после TerminateThread.
Конструктор класса VRWLock имеет следующие параметры:
lMaxReaders - максимальное количество читателей, которые могут одновременно читать ресурс (не должно быть = 0!). Значение по-умолчанию 65535.
dwSpinCount - количество неудачных попыток блокировки ресурса (занятого), после которых происходит переключение контекста с небольшой задержкой, определяемой параметром dwTimeout (в миллисекундах).
void LockRead(int lPosition, volatile LONG * lpThreadLock = NULL)
Блокировка ресурса читателем. Если ресурс занят писателем или превышено максимальное количество читателей, то происходит ожидание освобождения ресурса, когда удастся его заблокировать. Смотрите описание параметров в описании метода Lock класса VLock.
void LockWrite(int lPosition, volatile LONG * lpThreadLock = NULL)
Блокировка ресурса писателем. Если ресурс занят писателем или одним или несколькими читателями, то происходит ожидание освобождения ресурса, когда удастся его заблокировать. Смотрите описание параметров в описании метода Lock класса VLock.
void ReLockWrite(int lPosition, volatile LONG * lpThreadLock = NULL)
Изменение статуса блокировки с читателя на писателя. Если ресурс не занят ни читателем ни писателем, то действие функции аналогично LockWrite (блокировка писателем). Если ресурс занят одним читателем, то происходит переключение его статуса с читателя на писателя. Если ресурс занят писателем или более чем одним читателем, то происходит ожидание момента, когда ресурс будет не занят писателями и занят не более чем одним читателем. Смотрите описание параметров в описании метода Lock класса VLock.
void Unlock(volatile LONG * lpThreadLock = NULL)
Снятие блокировки.
static void OutputDebugLocks()
Вывод статистики блокировок (см. выше описание одноименного метода для класса VLock).
class VLockPtr, class VReadLockPtr, class VWriteLockPtr
Есть такая идиома: RAII - захват ресурса есть инициализация. Суть ее в следующем: создается класс-обертка такой, что в конструкторе класса вызывается соответствующая функция блокировки ресурса, а в деструкторе блокировка снимается. Это удобно по двум причинам:
Нет необходимости делать явный вызов Unlock (а это часто, как показывает практика, забывают сделать).
В случае возбуждения исключения между вызовами Lock и Unlock ресурс может оказаться занят “навсегда”. А при использования RAII, деструктор класса-обертки, а следовательно и Unlock, будет вызван и в случае исключительной ситуации.
VLockPtr - RAII класс-обертка над VLock.
VReadLockPtr - RAII класс-обертка над VRWLock::LockRead.
VWriteLockPtr - RAII класс-обертка над VRWLock::LockWrite.
unsignedint __stdcall LockPtrThreadProc(void * lpParam) { { VLockPtr lockptr(&lock, 1, reinterpret_cast(lpParam)); //lock resource //do something here } //unlock will be done here //contuinue working return0; }
===
Перепечатка материалов блога разрешается с обязательной ссылкой на blog.coolsoftware.ru
Вылезла сегодня с утра ошибка при компиляции любого проекта в Visual Studio 2010:
LINK : fatal error LNK1123: failure during conversion to COFF: file invalid or corrupt
Установка в свойствах проекта Linker->Enable Incremental Linking значения NO (/INCREMENTAL:NO) на помогла.
Полез смотреть, что же поменялось за последнее время. Оказалось вечером с авто-обновлениями винды поставился .NET Framework 4.5.1. Он то и нагадил!
1. Снес .NET Framework 4.5.1. Visual Studio перестал запускаться. 2. Установил .NET 4.0. Visual Studio починился, все проекты стали компилироваться нормально. 3. Слетел Mysql .Net Connector. Переустановил. Причем, Repair не помог, сделал сперва Remove, потом Install.
=== Перепечатка материалов блога разрешается с обязательной ссылкой на blog.coolsoftware.ru