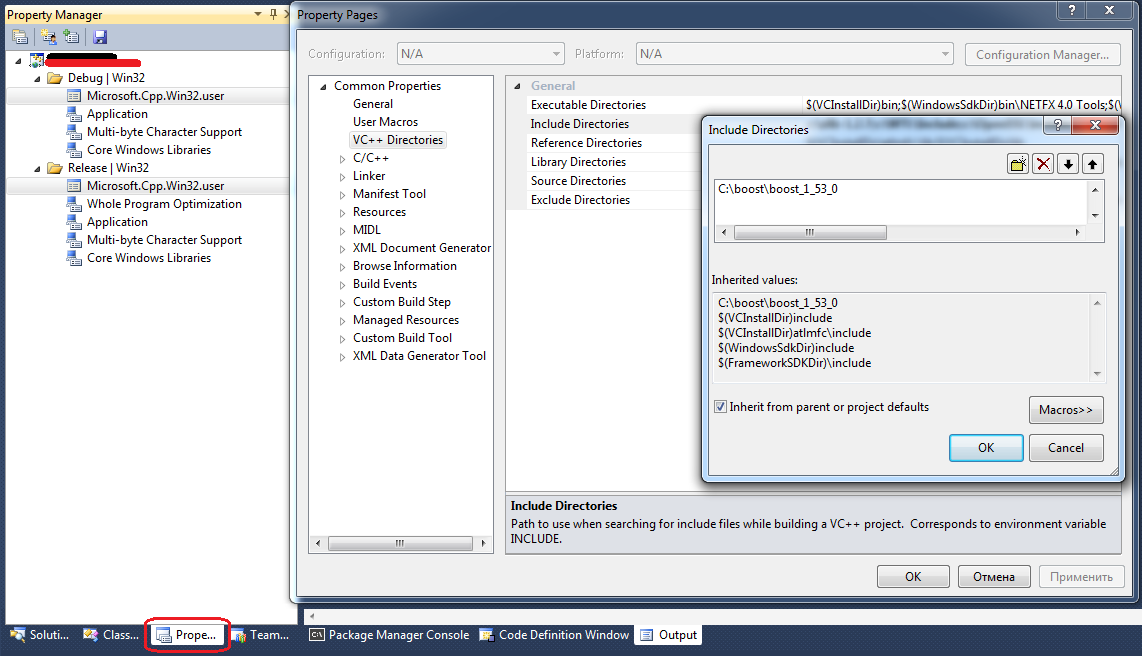
Дерево Интервалов (Отрезков)
Я уже несколько раз сталкивался с необходимостью решать следующую задачу: есть список интервалов и нужно найти один или все интервалы, в которые входит заданное значение. Пример: есть список диапазонов IP-адресов, каждому диапазону присвоен двух-буквенный код страны. Требуется для заданного IP-адреса определить страну.
Когда интервалов не много, то можно обойтись полным перебором (brute-force). Но когда их несколько десятков тысяч, а искать приходится часто, то нужна оптимизация.
Подходящая структура для быстрого поиска в списке интервалов называется “Дерево Интервалов” (Interval Tree) или “Дерево Отрезков”. Хорошее описание (англ.), а также пример реализации я нашел тут: http://www.drdobbs.com/cpp/interval-trees/184401179.
Теория
Коротко описание структуры дерева отрезков и алгоритма поиска приведу на примере: пусть есть список именованных отрезков:
a=[75, 76], b=[75, 79], c=[75, 84], |
Выпишем координаты вершин отрезков, отсортированные по-возрастанию:
X = {75, 76, 79, 80, 83, 84, 85, 90, 91, 92} |
Массив X содержит 10 элементов: X[0], X[1], …, X[9].
Возьмем среднее значение (медиану): 83 = X[m], m = (9-0) div 2.
Возможны три варианта расположения отрезков относительно медианы:
1. отрезки, которые содержат медиану.
2. отрезки, которые лежат слева от медианы.
3. отрезки, которые лежат справа от медианы.
Создадим узел дерева, который будет включать в себя значение медианы (дискриминант = 83) и список всех отрезков, которые содержат медиану:
R = {83, [c, f, g, h, i, j]} |
Оставшиеся отрезки слева от R: {a, b, d, e} и справа от R: {k, l, m}.
Построим левый узел дерева для отрезков {a, b, d, e}, находящихся левее медианы, рассматривая вершины слева от медианы: {75, 76, 79, 80}. Получим: O = {76, [a, b, d]}.
Аналогично правый узел для отрезков {k, l, m} и вершин {84, 85, 90, 91, 92}: U = {90, []}. Обратите внимание на возможность существования узлов, не содержащих отрезков.
Продолжая процесс рекурсивно, получим следующие узлы:
N = {75, []}, P = {79, [e]}, S = {84, [k]}, V = {91, [l, m]}, Q = {80, []}, T = {85, []}, W = {92, []}.
R |
R |
Алгоритм поиска выглядит следующим образом. Начинаем с вершины дерева. Сравниваем дискриминант текущего узла с искомым значением q. Если они равны (случай 1), то выводим все отрезки, на которые указывает текущий узел, и завершаем процесс. Если дискриминант текущего узла больше, чем q (случай 2), то перебираем все отрезки, на которые указывает текущий узел, и выводим такие, которые содержат q. Затем переходим к левому узлу. Если дискриминант текущего узла меньше, чем q (случай 3), то аналогично перебираем все отрезки текущего узла и выводим те, которые содержат q, а затем переходим к правому узлу.
В двух последних случаях (когда дискриминант узла не равен q) нужен перебор отрезков, на которые указывает узел. Этот перебор можно оптимизировать, если иметь два отсортированных массива отрезков: первый массив AL должен быть отсортирован по возрастанию левой (меньшей) координаты отрезка, а второй массив DH должен быть отсортирован по убыванию правой (большей) координаты отрезка. Для узла R из нашего примера:
AL = {c, f, g, h, i, j} |
Тогда, если дискриминант узла больше q (случай 2), то перебираем отрезки из массива AL до тех пор, пока левая координата отрезка не будет больше q. Если дискриминант узла меньше q (случай 2), то перебираем отрезки из массива DH до тех пор, пока правая координата отрезка не будет меньше q.
Практика
Реализацию дерева интервалов можно взять на github: https://github.com/coolsoftware/ITree.
Класс itree в itree.h.
За основу я взял реализацию Yogi Dandass, в которую добавил некоторые недостающие (ommited) определения, исправил пару багов и существенно оптимизировал построение дерева (метод construct_tree).
Баг 1 в методе itree::construct_tree. Код ниже вызывал выход за границы массива.
std::sort(&(al[list_start]), |
Он заменен на следующее:
std::sort(al.begin()+list_start, |
Баг 2 в методе query_iterator::init_node. Если value == cur_node->discrim, то требуется проверка, что cur_node->size != 0, а иначе возможен выход за границы массива.
void init_node(void) |
===
Перепечатка материалов блога разрешается с обязательной ссылкой на blog.coolsoftware.ru